WARNING
1、除本页设置外,同样受【配置选项】配置影响,这一块内容参考选项配置。
2、相同配置项,本页配置覆盖配置选项配置。
# 通配符
通配符,是介于纯文本匹配和正则表达式匹配之间的一种易理解并具有一定操作的匹配符合。
本软件仅支持两种通配符:*和?,注意通配符必须是英文字符(不是中文字符哦)。
*匹配一个或多个任意字符;?匹配一个任意字符。
# 限定网域
注意:此功能仅对页面网址有效,其他css/js/图片/字体等网址无效。

- (必填)匹配域名才被下载,当然您可以新增多组域名匹配,使用“|”分隔,表示“或”的关系。
- 使用通配符匹配
主机名(域名),即上图红色部分。
举个例子
当下载地址为https://www.example.com,网站还有子域名https://bj.example.com、https://sh.example.com、https://gz.example.com、https://sz.example.com 等北京/上海/广州/深圳等子分站。
1、下载主站和所有分站,设置值为:*.example.com,它匹配所有的域名。如果还要匹配根域名https://example.com,则设置为:*example.com。
2、下载主站和北京站:设置值为:www.example.com|bj.example.com,两组域名之间使用“|”分隔
# 限定路径
注意:此功能仅对页面网址有效,其他css/js/图片/字体等网址无效。

- (选填)匹配链成功接才被下载,当然默认留空不做任何限制,使用“|”分隔,表示“或”的关系。
- 使用通配符匹配
路径+查询参数,即上图绿色部分。
举个例子
网站地址/product/index.html和/contact/index.html
1、仅下载product目录下的页面,输入值为:/product/*
2、下载product和contact目录下的页面,输入值为:/product/*|/contact/*,两组匹配之间使用“|”分隔
如果需要做更加精准的匹配,请使用正则表达式做匹配:配置选项 > 下载范围 > 限定路径
# 排除路径
注意:此功能仅对页面网址有效,其他css/js/图片/字体等网址无效。
- (选填)与限定路径相反,匹配链接成功不会被下载,当然默认留空不做任何限制,使用“|”分隔,表示“或”的关系。
- 使用通配符匹配
路径+查询参数,即上图绿色部分。
举个例子
网站地址/product/index.html和/contact/index.html
1、product目录下的页面不下载,输入值为:/product/*
2、product和contact目录下的页面都不下载,输入值为:/product/*|/contact/*,两组匹配之间使用“|”分隔
# 最大深度
- (必填)输入下载的网址深度为1,这个网址html代码的链接深度为2,深度为2页面的链接深度为3,依次类推。
- 下载页面的深度,大于设置深度的页面不会被下载。
- 下载顺序:按深度从小到大下载
- 同一网址,从不同页面进入,深度不一样是,深度取最小值。
举个例子
当下载地址为https://www.example.com
1、首页深度为1
2、首页点击列表页,列表页深度为2
3、列表页点击详情页,详情页深度为3
4、详情页点击下一篇文章,下一篇文章深度为4
# 最大页数
- (必填)下载最多页面数量,已下载页数大于设置页数的页面不会被下载。
- 一个网址代表一页
- 这是设置一个上限值,根据个人需求设置。
举个例子
比如设置下载页数设置为5000页
1、假设网站一共有1000页,那么这1000页全部下载。
2、假设网站一共有20000页,按深度从小到大顺序下载5000页,剩余的15000页不会下载。
温馨提示
- 下载的页数越多,要求电脑内存/CPU/硬盘越高。
- CPU越快处理速度越快。
- 一般百万级数据,至少配置16G内存,另外设置足够的虚拟内存做为备用。
# 页面结构
指的是html页面保存目录结构。
- 自动选择:当所有页面数量小于3000时,使用"保存到根目录",否则使用"与原站一致"
- 与原站一致:原站页面URL是在A目录,下载后就保存在A目录下。
- 保存到根目录:所有页面都保存在根目录。
# 文件结构
这里指的是除html页面以外的所有资源文件,例如js、css、image、font、file等。
- 与原站一致:原站文件URL是在A目录,下载后就保存在A目录下。
- 保存到配置目录,可以在
配置选项的系统设置-文件路径中配置。
# 编码改成
- 下载后自动将编码修改为指定的编码。
- 现在大多数网站采用utf-8编码,少数网站采用gbk编码,我们软件能99.99%正确识别网站编码(包含一站多编码的页面),软件自动删除和修改代码里的编码,包含html代码charset编码css代码charset编码。
# 下载超时
- 下载一个请求超时时间,第一次超时软件会重试一次,所以如果一个非常慢的链接,第一次请求失败后再次请求失败,等待时间为设置的2倍。
- 建议:网站很快可以设置时间短些,以减少等待时间;网站很慢或下载大文件,必须设置超时时间大些,不然这些慢页面和大文件都会下载失败。
- 软件默认为30秒,这个不是越长越好,也不是越短越好。
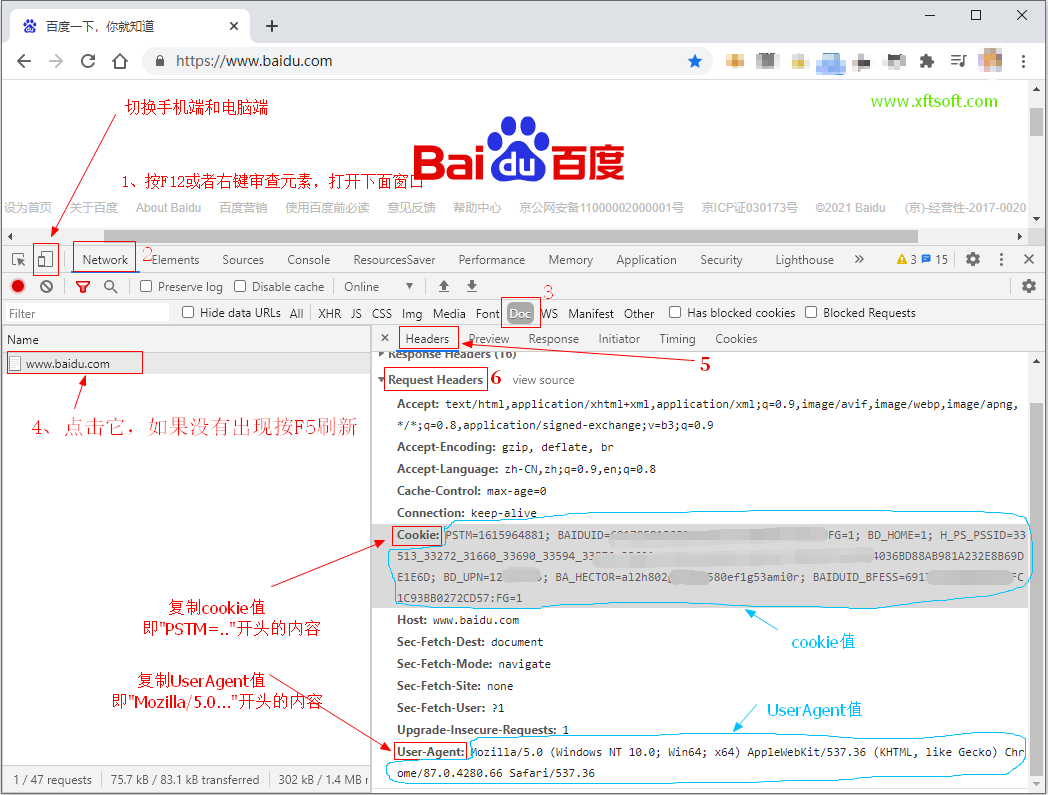
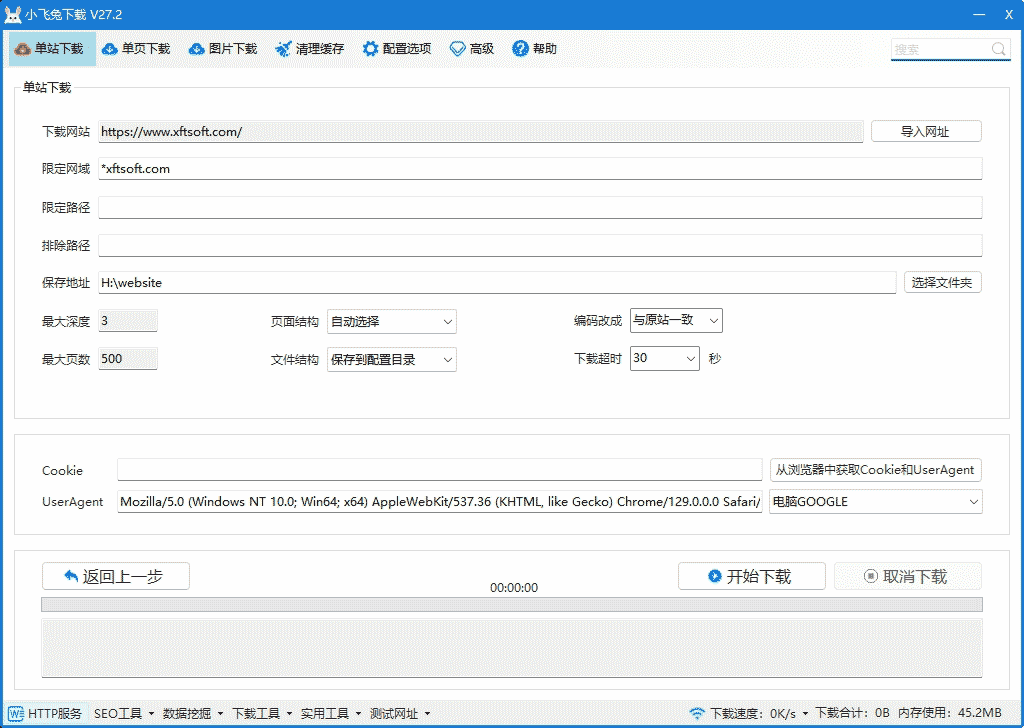
# Cookie
- 一般为增强验证页面或登录页面才需要用到,参考网址:https://www.xftsoft.com/news/jiaocheng/cookie-useragent.html
# UserAgent
- 服务器使用此值识别用户使用的是电脑端还是手机端。
- 自定义设置参考上面Cookie链接里的方法打开控制台后可以看到有个叫User-Agent的,就是它,复制值到文本框即可。