WARNING
1. In addition to the settings on this page, the settings are also affected by the [Configuration Options] settings. Please refer to the option configuration for details.
2. Same configuration items,This page configurationcoverConfiguration optionsConfiguration.
# wildcard
Wildcards are a type of matching symbol that is easy to understand and has certain operational capabilities, falling between plain text matching and regular expression matching.
This software only supports two wildcard characters:*and?Note that wildcard characters must be English characters (not Chinese characters).
*Matches one or more arbitrary characters;?Matches any single character.
# Limited Domain
Note: This function only applies to page URLs; it does not apply to other URLs such as CSS/JS/images/fonts.

- (Required) Only matching domains will be downloaded. Of course, you can add multiple sets of domains to match, separated by "|" to indicate an "or" relationship.
- Use wildcard matching
Hostname (domain name)That is, the red part in the image above.
For example
When the download address ishttps://www.example.comThe website also has subdomains.https://bj.example.com、https://sh.example.com、https://gz.example.com、https://sz.example.com Substations in Beijing, Shanghai, Guangzhou, Shenzhen, etc.
1. Download the main site and all sub-sites, set the value to:*.example.comIt matches all domain names. If you also want to match the root domain...https://example.comThen set it to:*example.com。
2. Download the main site and Beijing site: Set the value to:www.example.com|bj.example.comThe two sets of domain names are separated by "|".
# Path restriction
Note: This function only applies to page URLs; it does not apply to other URLs such as CSS/JS/images/fonts.

- (Optional) Download is only allowed if the matching chain is successful. Of course, the default is to leave it blank without any restrictions. Use "|" as a separator to indicate an "or" relationship.
- Use wildcard matching
Path + query parametersThis refers to the green part in the image above.
For example
Website address../../../product/and../../../404.html
1. Download onlyproductThe page in the directory, the input value is:/product/*
2. DownloadproductandcontactThe page in the directory, the input value is:/product/*|/contact/*Two sets of matches are separated by "|".
For more precise matching, please use regular expressions: Configuration Options > Download Range > Limit Path
# Exclusion Path
Note: This function only applies to page URLs; it does not apply to other URLs such as CSS/JS/images/fonts.
- (Optional) The opposite of limiting the path, a successfully matched link will not be downloaded. Of course, the default is to leave it blank without any restrictions. Use "|" as a separator to indicate an "or" relationship.
- Use wildcard matching
Path + query parametersThis refers to the green part in the image above.
For example
Website address../../../product/and../../../404.html
1、productDo not download pages in the directory. Enter the following value:/product/*
2、productandcontactDo not download any pages in the directory. Enter the following value:/product/*|/contact/*Two sets of matches are separated by "|".
# Maximum depth
- (Required) Enter the URL to download with a depth of 1. The HTML code of this URL has a link depth of 2. The page with a link depth of 2 has a link depth of 3, and so on.
- The download depth is set; pages exceeding the set depth will not be downloaded.
- Download order: Download from lowest to highest depth
- When accessing the same URL from different pages, the depth will vary, and the minimum depth will be taken.
For example
When the download address ishttps://www.example.com
1、HomeDepth 1
2、HomeClickList Page,List PageDepth 2
3、List PageClickDetails Page,Details PageDepth 3
4、Details PageClickNext article,Next articleDepth 4
# Maximum number of pages
- (Required) Maximum number of pages to download. Pages that have already been downloaded more than the set number of pages will not be downloaded.
- One URL represents one page
- This is to set an upper limit value, which can be set according to individual needs.
For example
For example, setting the download page count to...5000Page
1. Assume the website has a total of1000Page, then this1000Download all pages.
2. Assume the website has a total of20000Pages, downloaded in ascending order of depth.5000Pages remaining15000The page will not be downloaded.
Kind tips
- The more pages you download, the higher the requirements for your computer's memory, CPU, and hard drive.
- The faster the CPU, the faster the processing speed.
- For datasets with millions of records, at least 16GB of RAM is required, with an additional amount of virtual memory allocated as a backup.
# Page Structure
This refers to the directory structure saved in an HTML page.
- Automatic selection: When the total number of pages is less than 3000, use "Save to root directory"; otherwise, use "Same as original site".
- Consistent with the original site: The original site's page URL is in directory A, and the downloaded page will be saved in directory A.
- Save to root directory: All pages are saved in the root directory.
# File Structure
This refers to all resource files other than the HTML page, such as JS, CSS, images, fonts, and files.
- Consistent with the original site: The original site's file URL is in directory A, and the downloaded file will be saved in directory A.
- Save it to the configuration directory, and you can...
Configuration optionsofSystem Settings-File pathMedium configuration.
# Encoding changed to
- After downloading, the encoding will be automatically changed to the specified encoding.
- Most websites now use UTF-8 encoding, while a few use GBK encoding. Our software can correctly identify website encoding with 99.99% accuracy (including pages with multiple encodings on one site). The software automatically deletes and modifies the encoding in the code, including charset encoding in HTML code and charset encoding in CSS code.
# Download timed out
- The download request timeout period is set. The software will retry once the first timeout occurs. Therefore, if the link is very slow, and the first request fails, the waiting time will be twice the set timeout period.
- Recommendation: For websites that are fast, set a shorter timeout to reduce waiting time; for slow websites or downloading large files, you must set a longer timeout, otherwise these slow pages and large files will fail to download.
- The software defaults to 30 seconds, which is neither better the longer nor the shorter the better.
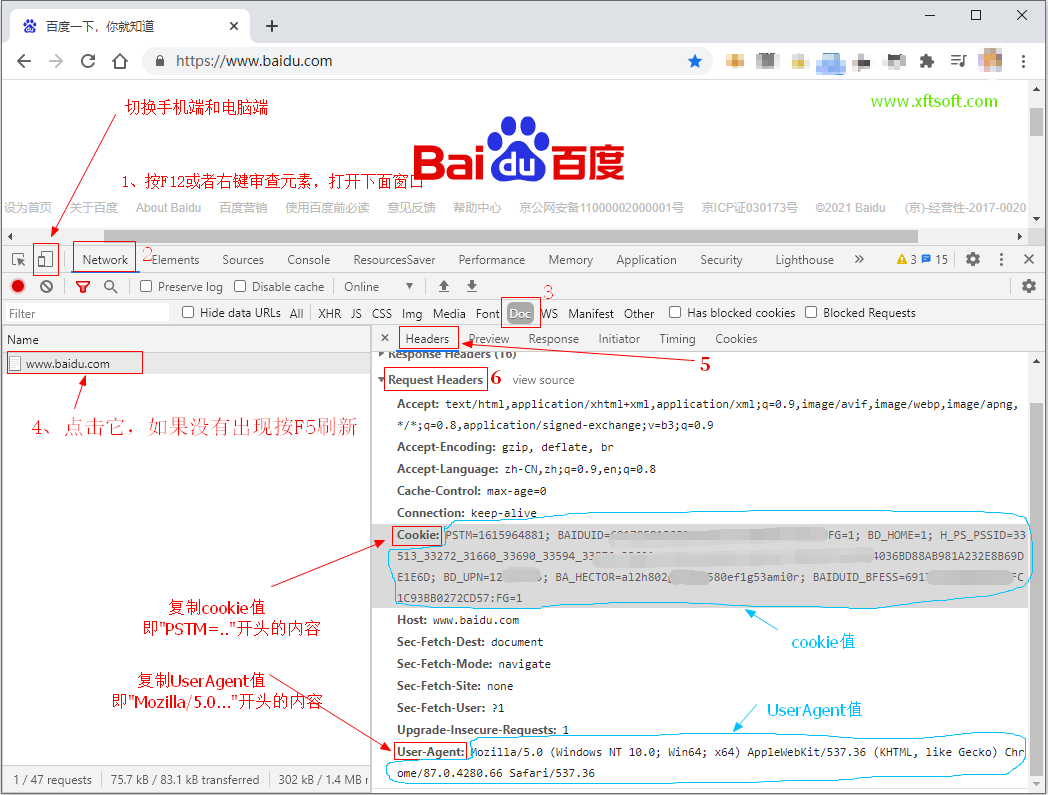
# Cookie
- This is generally used to enhance verification pages or login pages. See the reference URL:../../../news/jiaocheng/cookie-useragent.html
# UserAgent
- The server uses this value to identify whether the user is using a computer or a mobile device.
- For custom settings, refer to the method in the Cookie link above. After opening the console, you will see a field called User-Agent. That's it. Copy the value into the text box.